Job workers
A job worker is a service capable of performing a particular task in a process.
Each time such a task needs to be performed, this is represented by a job.
A job has the following properties:
- Type: Describes the work item and is defined in each task in the process. The type is referenced by workers to request the jobs they are able to perform.
- Custom headers: Additional static metadata that is defined in the process. Custom headers are used to configure reusable job workers (e.g. a
notify Slackworker might read out the Slack channel from its header.) - Key: Unique key to identify a job. The key is used to hand in the results of a job execution, or to report failures during job execution.
- Variables: The contextual/business data of the process instance required by the worker to do its work.
Requesting jobs
Job workers request jobs of a certain type on a regular interval (i.e. polling). This interval and the number of jobs requested are configurable in the Zeebe client.
If one or more jobs of the requested type are available, Zeebe (the workflow engine inside Camunda 8) will stream activated jobs to the worker. Upon receiving jobs, a worker performs them and sends back a complete or fail command for each job, depending on if the job could be completed successfully.
For example, the following process might generate three different types of jobs: process-payment, fetch-items, and ship-parcel:

Three different job workers, one for each job type, could request jobs from Zeebe:
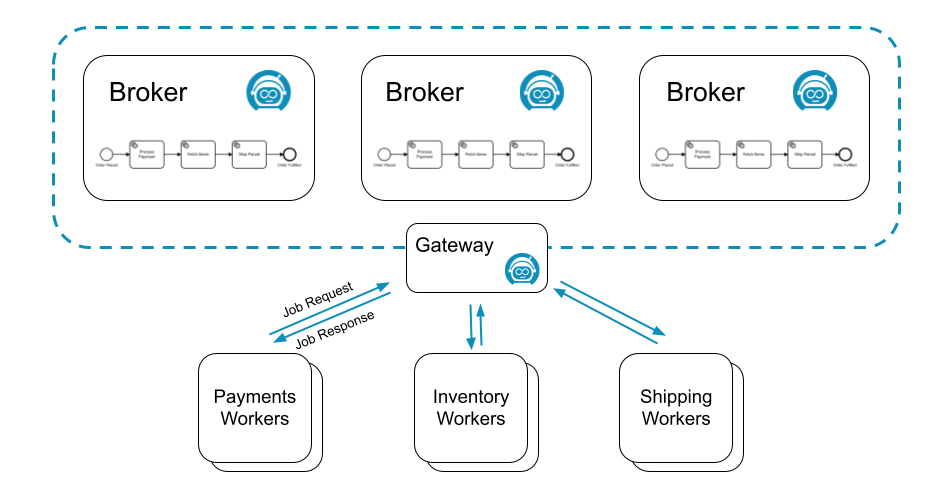
Many workers can request the same job type to scale up processing. In this scenario, Zeebe ensures each job is sent to only one of the workers.
Such a job is considered activated until the job is completed, failed, or the job activation times out.
On requesting jobs, the following properties can be set:
- Worker: The identifier of the worker. Used for auditing purposes.
- Timeout: The time a job is assigned to the worker. If a job is not completed within this time, it can be reassigned by Zeebe to another worker.
- MaxJobsToActivate: The maximum number of jobs which should be activated by this request.
- FetchVariables: A list of required variables names. If the list is empty, all variables of the process instance are requested.
Long polling
Ordinarily, a request for jobs can be completed immediately when no jobs are available.
To find a job to work on, the worker must poll again for available jobs. This leads to workers repeatedly sending requests until a job is available.
This is expensive in terms of resource usage, because both the worker and the server are performing a lot of unproductive work. Zeebe supports long polling for available jobs to better utilize resources.
With long polling, a request will be kept open while no jobs are available. The request is completed when at least one job becomes available.
Long Polling is set during job activation with the parameter request-timeout.
Job queueing
Zeebe decouples creation of jobs from performing the work on them. It is always possible to create jobs at the highest possible rate, regardless if there is a job worker available to work on them. This is possible because Zeebe queues jobs until workers request them.
This increases the resilience of the overall system. Camunda 8 is highly available so job workers don't have to be highly available. Zeebe queues all jobs during any job worker outages, and progress will resume as soon as workers come back online.
This also insulates job workers against sudden bursts in traffic. Because workers request jobs, they have full control over the rate at which they take on new jobs.
Completing or failing jobs
After working on an activated job, a job worker informs Camunda 8 that the job has either completed or failed.
- When the job worker completes its work, it sends a
complete jobcommand along with any variables, which in turn is merged into the process instance. This is how the job worker exposes the results of its work. - If the job worker can not successfully complete its work, it sends a
fail jobcommand. Fail job commands include the number of remaining retries, which is set by the job worker.- If
remaining retriesis greater than zero, the job is retried and reassigned. - If
remaining retriesis zero or negative, an incident is raised and the job is not retried until the incident is resolved.
- If
When failing a job it is possible to specify a retry back off. This back off allows waiting for a specified amount of time before retrying the job.
This could be useful when a job worker communicates with an external system. If the external system is down, immediately retrying the job will not work.
This will result in an incident when the retries run out. Using the retry back off will delay the retry. This allows the external system some time to recover.
If no retry back off the job is immediately retried.
When Completing or failing jobs with variables, the variables are merged into the process at the job's associated task.
- When
Completing a jobthe variables are propagated from the scope of the task to its higher scopes. - When
Failing a jobthe variables are only created in the local scope of the task.
There are several advantages when failing a job with variables. Consider the following use cases:
- You can fail a job and raise an incident by setting the job
retriesto zero. In this case, it would be useful to provide some additional details through a variable when the incident is analyzed. - If your job worker can split the job into smaller pieces and finish some but not all of these, it can fail the job with variables indicating which parts of the job were successfully finished and which weren't. Such a job should be failed with a positive number of retries so another job worker can pick it up again and continue where the other job worker left off. The job can be completed when all parts are finished by a job worker successfully.
Timeouts
If the job is not completed or failed within the configured job activation timeout, Zeebe reassigns the job to another job worker. This does not affect the number of remaining retries.
A timeout may lead to two different workers working on the same job, possibly at the same time. If this occurs, only one worker successfully completes the job. The other complete job command is rejected with a NOT FOUND error.
The fact that jobs may be worked on more than once means that Zeebe is an "at least once" system with respect to job delivery and that worker code must be idempotent. In other words, workers must deal with jobs in a way that allows the code to be executed more than once for the same job, all while preserving the expected application state.